作为普通译者,术语管理的功能其实很简单,主要就是便于整理词语,统一译文,加快输入效率。
而Lisa提出的TBX标准则定义了单词的领域、定义、用法、词性、阴阳性、缩写、同义词、与其它词语的关联等一系列标签,较为复杂。SDL Multiterm和MemoQ的术语模块都参考了TBX的设计。
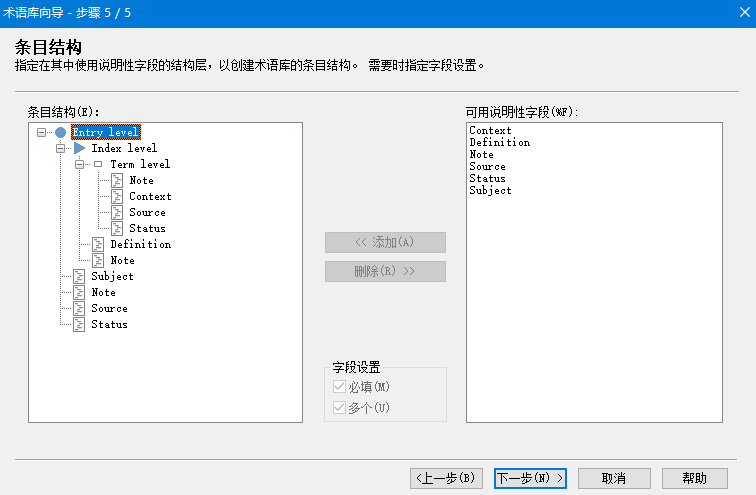
另外还有把TBX转换为RDF用于描述实体(ontology),就更为复杂了,适合相关研究人员使用。
BasicCAT术语管理使用起来很简单,足够满足一般需求。
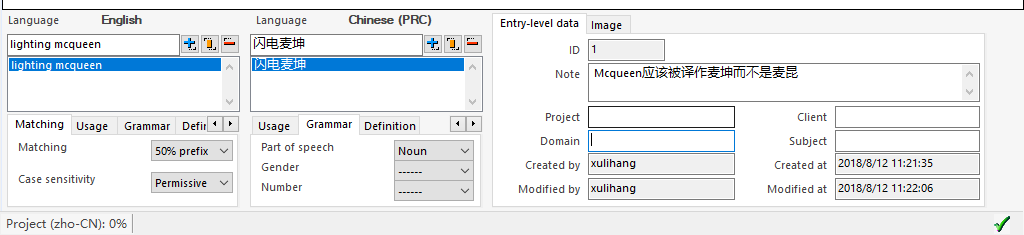
首先是基本的划词添加。在原文和译文输入框中划取要添加的术语,然后在右边的术语区点击添加术语。
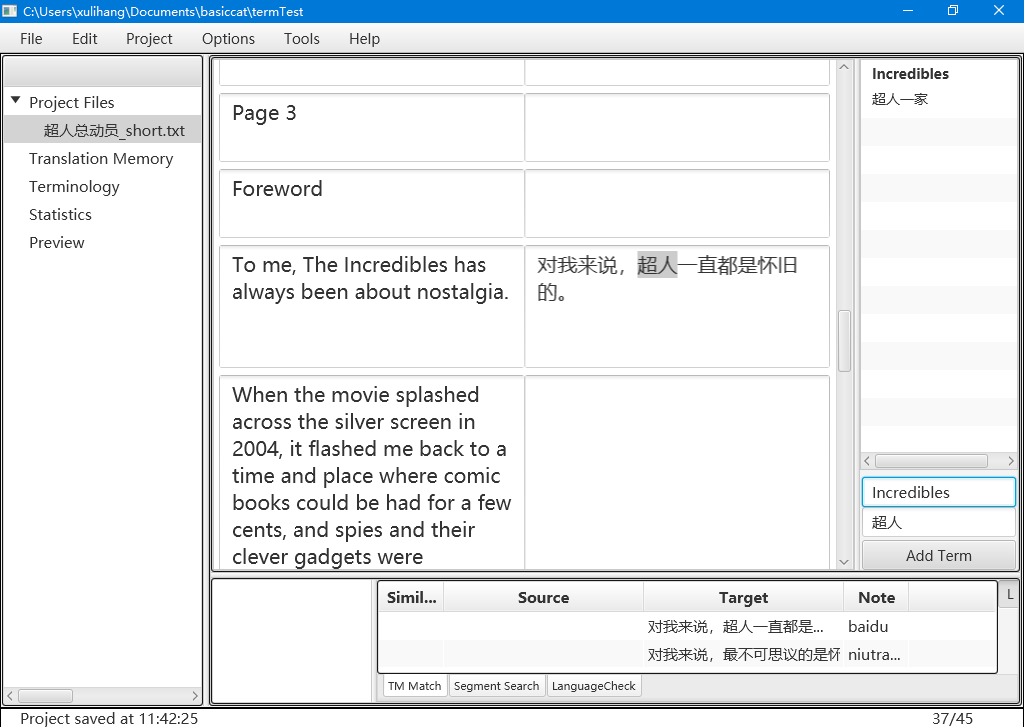
这里要注意的是,术语原文一样,但表达的概念可能不一样。比如test,可以表示试验,也可以表示测试。所以,一个原文键值可以存储多个对应的译文。这对应TBX中的多个termEntry。
添加后的术语可以在术语管理器中进行进一步的管理。可以删除条目、修改条目、快速检索、添加标签和备注。
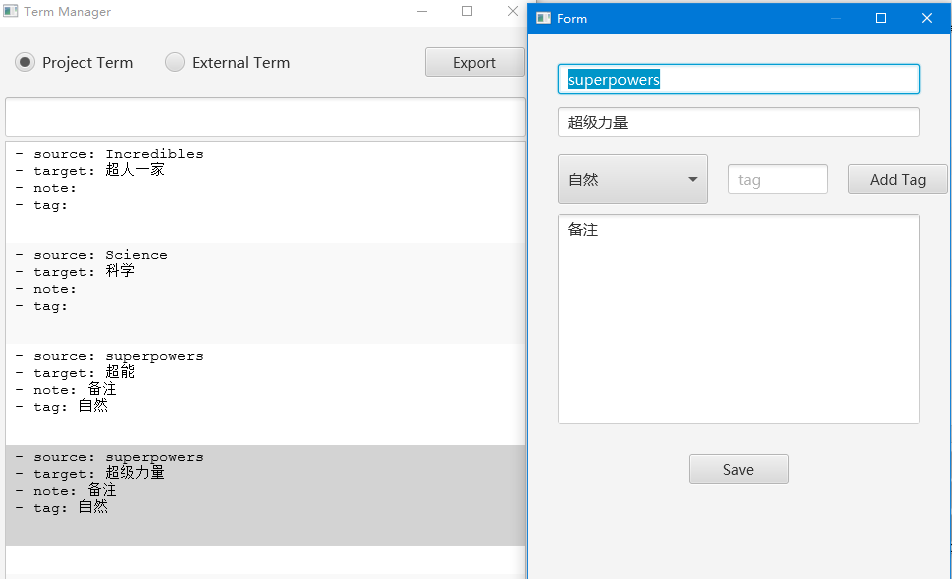
另外还要支持TBX和TXT格式的导入导出。TXT以Tab分隔,依次是原文、译文、备注和标签。
TBX的话,标签对应subjectField,备注放在note标签里。一个生成的TBX文件如下:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<martif type="TBX" xml:lang="en-US">
<martifHeader>
<fileDesc>
<titleStmt>
<title>
<Text>Exported Term</Text>
</title>
</titleStmt>
<sourceDesc>
<p>
<Text>Created by BasicCAT</Text>
</p>
</sourceDesc>
</fileDesc>
</martifHeader>
<text>
<body>
<termEntry id="eid-BasicCAT-0">
<langSet xml:lang="en">
<tig>
<term>
<Text>Incredibles</Text>
</term>
</tig>
</langSet>
<langSet xml:lang="zh">
<tig>
<term>
<Text>超人一家</Text>
</term>
</tig>
</langSet>
</termEntry>
<termEntry id="eid-BasicCAT-1">
<langSet xml:lang="en">
<tig>
<term>
<Text>Science</Text>
</term>
</tig>
</langSet>
<langSet xml:lang="zh">
<tig>
<term>
<Text>科学</Text>
</term>
</tig>
</langSet>
</termEntry>
<termEntry id="eid-BasicCAT-2">
<descrip type="subjectField">自然</descrip>
<langSet xml:lang="en">
<tig>
<term>
<Text>superpowers</Text>
</term>
</tig>
</langSet>
<langSet xml:lang="zh">
<tig>
<term>
<Text>超能</Text>
</term>
<note>
<Text>备注</Text>
</note>
</tig>
</langSet>
</termEntry>
<termEntry id="eid-BasicCAT-3">
<descrip type="subjectField">自然</descrip>
<langSet xml:lang="en">
<tig>
<term>
<Text>superpowers</Text>
</term>
</tig>
</langSet>
<langSet xml:lang="zh">
<tig>
<term>
<Text>超级力量</Text>
</term>
<note>
<Text>备注</Text>
</note>
</tig>
</langSet>
</termEntry>
</body>
</text>
</martif>
另外还有术语的匹配问题,如果添加的术语有屈折变化,在检索时需要对其进行词型还原。比如动词的第三人称单数和复数形式。这里我采用opennlp对原文进行分词、词性标注,并最终调用lemma词典得到单词的原型。就是opennlp的模型不多,不过有英文的就够了。
再有就是术语匹配的效率问题,目前我想了两种术语匹配方法。一种是遍历术语库,看看哪个条目在原文中存在。另一种是把原文做成ngam,默认长度是1-8个,然后在术语库中匹配,因为使用的hashmap,效率会高很多。这适用于术语库条目很多的情况。一个缺点是不能对条目中的原文进行词性还原。
相关文件:
https://github.com/xulihang/BasicCAT/blob/master/BasicCAT/Term.bas
https://github.com/xulihang/BasicCAT/blob/master/BasicCAT/TermEditor.bas
https://github.com/xulihang/BasicCAT/blob/master/BasicCAT/TermManager.bas
https://github.com/xulihang/BasicCAT/blob/master/BasicCAT/opennlp.bas