
我们的大创是对美剧版甄嬛传的英文字幕进行翻译相关的研究,由于研究需要,需要提取纯文本的字幕。我在网上搜遍了美剧甄嬛传的字幕也没有找到字幕文件下载,一度放弃。结果几个月后的今天,我想起netflix上可以打开关闭字幕,还可以选择英文和西班牙字幕,字幕应该不是融合在视频里的,于是重启开启了netflix会员,想把netflix上的字幕提取出来。
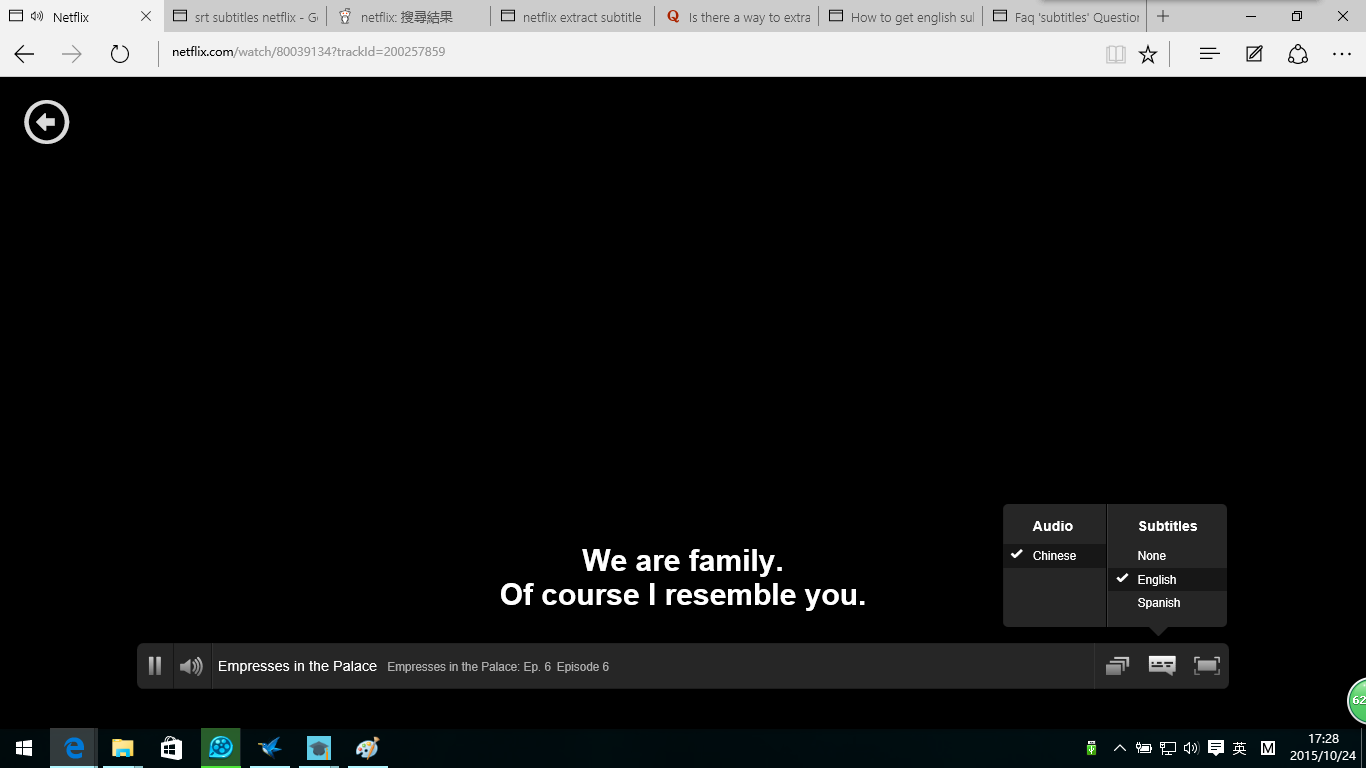
我先是在网上用netflix字幕提取和extract subtitles netflix搜索,结果没有找到可行的办法。想想还是自己用浏览器的开发者工具找吧。
试了之后发现很简单地就把字幕文件提取出来了。
打开浏览器的开发者调试工具,我这里直接用win10上的edge自带的调试工具,点网络,查看捕捉到的请求。
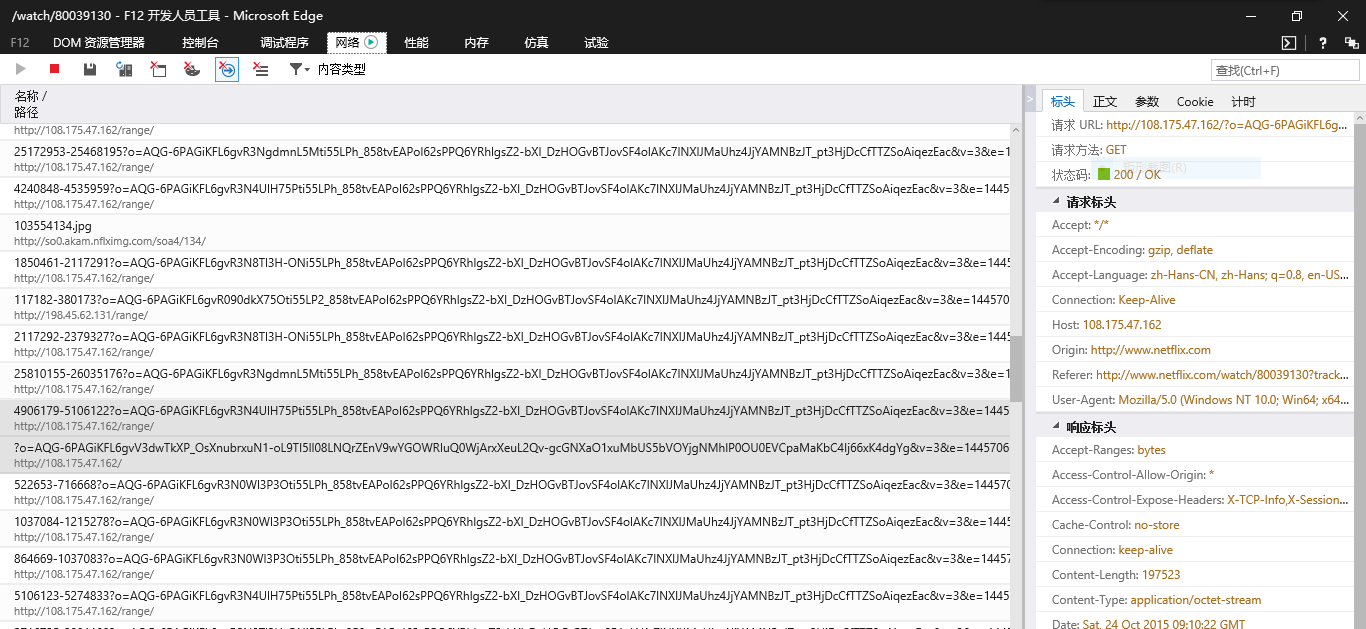
光看URL的确没有可读的英文告诉我哪个是字幕文件,但比较发现主要有一个URL,是以ip/range开头的,应该是视频的分段文件。然而有一个url同样以这个ip开头,却没有了range,下载这个文件,打开后发现是xml格式的字幕文件!
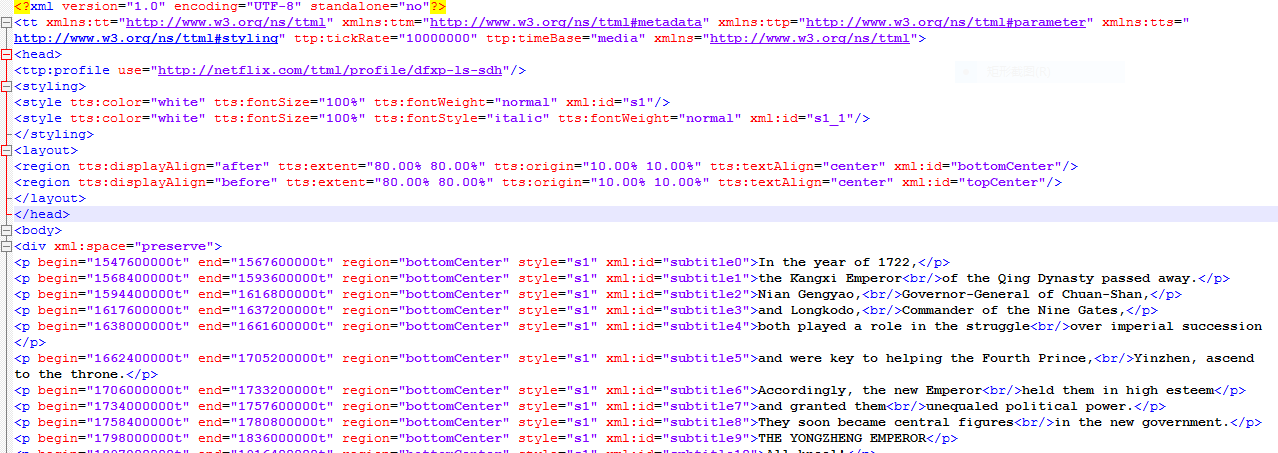
这里在放上一段提取到的字幕文件的url:http://108.175.47.162/?o=AQG-6PAGiKFL6gvV3dwTkXP_OsXnubrxuN1-oL9TI5ll08LNQrZEnV9wYGOWRIuQ0WjArxXeuL2Qv-gcGNXaO1xuMbUS5bVOYjgNMhlP0OU0EVCpaMaKbC4Ij66xK4dgYg&v=3&e=1445706614&t=pihXKkZxMeRMabM-roZFmxK9mSg
好了,因为是重启的会员,没有新会员一个月的免费优惠了,我还是好好看看netflix上的视频,让9.99美元的订阅费有点价值吧。。
更新:
##把xml的字幕文件转为srt格式
纯文本处理这样的一行内容:<p begin="1547600000t" end="1567600000t" region="bottomCenter" style="s1" xml:id="subtitle0">In the year of 1722,</p>
里面包含了开始时间,结束时间和字幕内容,其中的时间数据除以1+e10就是秒了。
因为比较简单,我也不贴我丑陋的代码了。最后输出结果如下:
1
00:02:34,000-->00:02:36,000
In the year of 1722,
2
00:02:36,000-->00:02:39,000
the Kangxi Emperor of the Qing Dynasty passed away.
2018/10/18更新:
有朋友问我字幕获取的事,截至目前,上述的方法还是有效的。但是开浏览器调试工具可能比较难以找到地址,一般会获取大量以下这段地址的内容:
https://ipv4-c001-pdx001-ix.1.oca.nflxvideo.net/range/412380277-413177770?o=AQHthFS3s9YFW93IkMVXxQVsZTdduAMLzLxISI28vT9LfI53tHBBEi9...
然后字幕文件的地址是以下格式的:
https://ipv4-c001-pdx001-ix.1.oca.nflxvideo.net/?o=AQG_NH7i3YyyPn7m4oCIvfJXeH9xkKcjLa3jhQeYzC1f0hopvWakPz_T7l6ZJ1xrq2wlqYNayqCeGDA9kt8qk8Eon0cBNfh52hXyTlVuFccavCEzWIx_1-W0y1ZGssr9...
可以根据第一个地址找第二个地址的内容。
测试中文字幕找不到第二个地址。有高手修改了netflix播放器的脚本,利用fiddler截取播放器脚本,替换为修改过的,然后播放视频时会自动跳转到字幕地址。中文字幕格式是WEBVTT而不是ttml。因为不让放,我这里也就不给出脚本了。