最近综合实践的项目是研究交互式机器翻译,我搜了不少文献进行阅读。对这方面也有了一点了解。
交互式机器翻译(interactive machine translation)最早是1997年由Foster提出的,当时的项目叫TransType,此后不断发展。大抵是机器翻译提供一个参考译文,然后随着用户的输入(前缀发生变化,prefix),提供不同的参考内容(后缀,suffix)。一般机器翻译系统和翻译界面都是耦合的,机器翻译系统被修改以适应交互式机器翻译的需要。这往往需要开发者对机器翻译系统有相当深刻的了解,比如欧盟的CASMACAT系统的开发者之一就是开源的统计式机器翻译Moses的开发者。
在2014年,Pérez-Ortiz等人提出了一个黑盒的方法。它可以使用任意机器翻译系统、翻译记忆和双语词典提供的双语资源,为翻译提供参考。该方法将原文以n-gram的办法分为多个片段,然后每个片段都利用双语资源进行翻译,然后根据一定的排序方法(目前是简单的距离方法),给用户提供有限的几个建议。用户输入一个前缀,就会做进一步筛选。因为使用了各种双语资源,再叫交互式机器翻译就不合适了,一般叫做交互式翻译预测。
Daniel Torregrosa等人开发了Forecat这一黑盒式的交互式翻译预测系统,它最初是一个java写web工具。后来又开发了OmegaT的Forecat插件,利用了OmegaT的机器翻译与自动完成功能。
这个插件我试用下来还是很不错的,因为机器翻译在句子级别很难做得完善,但是以语块为单位使用机器翻译,可以给翻译提供很大的帮助。
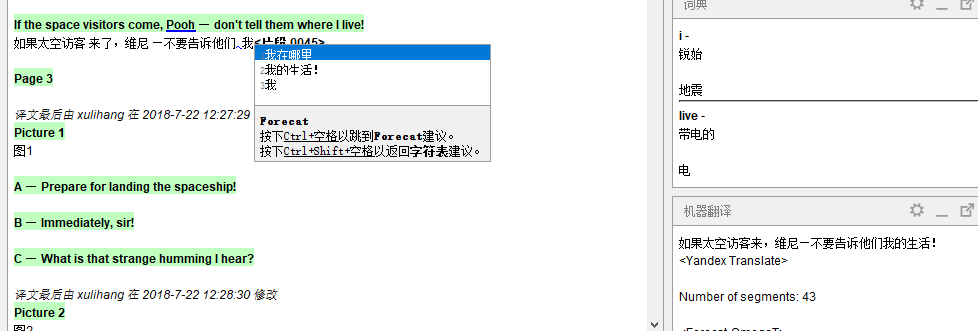
不过Forecat目前还有不完善的地方,比如输入的中文需要空格才能提示下一部分的翻译,自动完成时还会在结尾处加上空格,对中文这样没有分词的语言支持的不好。我给作者提了一个issue:https://github.com/transducens/Forecat-OmegaT/issues/9
Forecat-OmegaT的使用方法:
- 在此https://github.com/transducens/Forecat-OmegaT/releases下载插件,复制到omegat的plugins文件夹。
- OmegaT需要设置一个机器翻译,我用的Yandex,它目前是免费使用的。
- 更多复杂的方法,比如自己训练神经网络,我也不太会。。
参考文献:
- Alabau, V., Bonk, R., Buck, C., Carl, M., Casacuberta, F., García-Martínez, M., . . . Tsoukala, C. (2013). CASMACAT: An Open Source Workbench for Advanced Computer Aided Translation. The Prague Bulletin of Mathematical Linguistics, 100(1), 101-112.
- Peris, Á., Domingo, M., & Casacuberta, F. (2017). Interactive neural machine translation. Computer Speech & Language, 45, 201-220.
- Daniel, T., Mikel L, F., & Juan Antonio, P.-O. (2014). An Open-Source Web-Based Tool for Resource-Agnostic Interactive Translation Prediction. The Prague Bulletin of Mathematical Linguistics, 102(1), 69-80.