本地化课的期末作业,我写了下,觉得内容比较详尽了,现在发上来,虽然很多地方我讲得很简略。
目录
本地化和翻译的一个区别在于翻译内容的多样化,可能需要翻译应用软件、网页或者音视频等多媒体内容,同时还要针对译入语文化对内容适当进行修改。
开源翻译工具对于其它开源界使用的技术有广泛支持,而且因为其开源的性质,很容易自由地进行功能上的扩展。除了商业软件中使用的格式,很多在开源软件中有广泛应用的格式,如本地化技术gettext使用的文件格式PO,开源翻译工具OmegaT、Okapi等都支持。OmegaT是专业的计算机辅助翻译软件,而Okapi是用于翻译与本地化的一套工具集。
下面将结合本地化流程,讲解作为一个本地化工程师,可以利用开源工具做什么(主要使用OmegaT和Okapi)。
前期工程
辨识语言资源
本地化工程师需要辨识语言资源,然后做成翻译项目分发给译员进行翻译。
比如要进行软件UI的翻译,需要提取如.NET的资源文件(.resx)、Java使用的properties文件、iOS使用的strings文件和Android使用的xml文件等。网页的翻译可能需要处理htm、php和json等格式的文件。而文档的翻译,需要处理markdown、docbook、dita和restructuredText等格式的文件。
处理文件格式
上面提到的文件格式,OmegaT大部分都支持,可以直接导入。但是OmegaT默认不支持Markdown和restructuredText这样的格式,以下是解决办法:
对于Markdown,我们可以使用Okapi Framework来进行处理,有两种办法。
1、直接使用Okapi为OmegaT提供的过滤器插件
安装说明在Okapi官网的OmegaT插件页面。需要下载如下图的插件文件,并复制到OmegaT安装目录下的plugins文件夹。
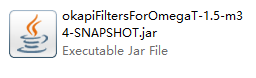
安装后可以给OmegaT添加如下格式的支持,其中便包括Markdown。
- Doxygen-commented files (using the Doxygen Filter)
- HTML files (using the HTML Filter)
- InDesign IDML files (using the IDML Filter)
- JSON files (using the JSON Filter)
- Markdown files (using the Markdown Filter)
- Qt TS files (using the TS Filter)
- Trados TagEditor TTX files (using the TTX Filter)
- Transifex projects (using the Transifex Filter)
- Wordfast Pro TXML files (using the TXML Filter)
- XLIFF 1.2 documents (using the XLIFF Filter)
- XLIFF 2 documents (see more information)
- XML files (using the XML Filter)
- XML files (using the XML Stream Filter)
- YAML files (using the YAML Filter)
2、将Markdown转换为XLIFF
另一种方法是使用Okapi的Rainbow工具将Markdown转换OmegaT支持的XLIFF格式文件。XLIFF是XML本地化数据交换格式(XML Localization Interchange File Format )的缩写,它相当于本地化过程中使用的一种中间格式。我们可以将CAT软件不支持的源文件格式转换为XLIFF,再基于翻译后的XLIFF生成目标格式。
我们首先将Markdown文件导入Rainbow:
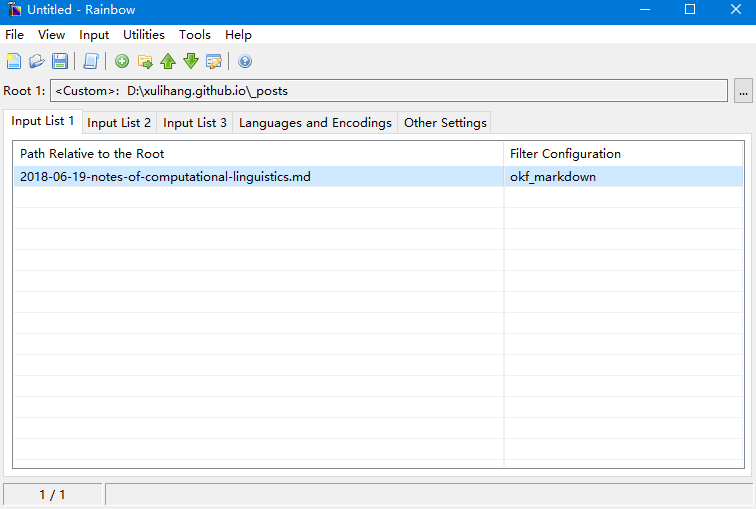
点击Languages and Encodings标签可以设置源语言和目标语言。
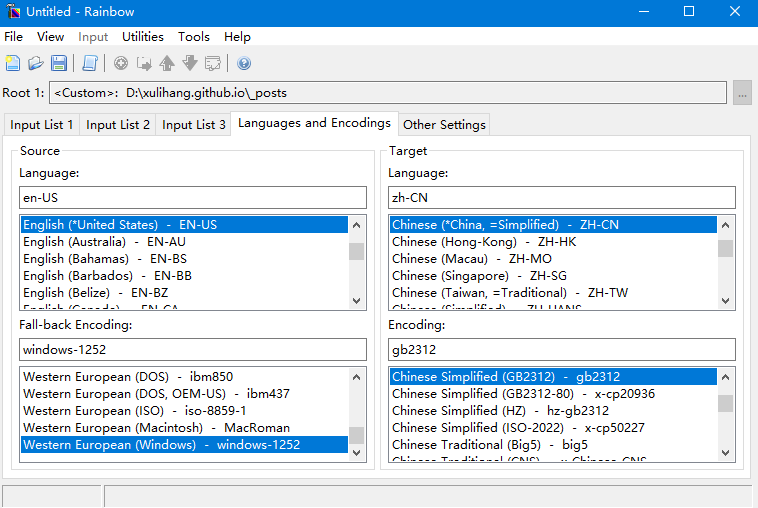
然后,点击菜单栏的Utilities->Translation -Kit Creation。
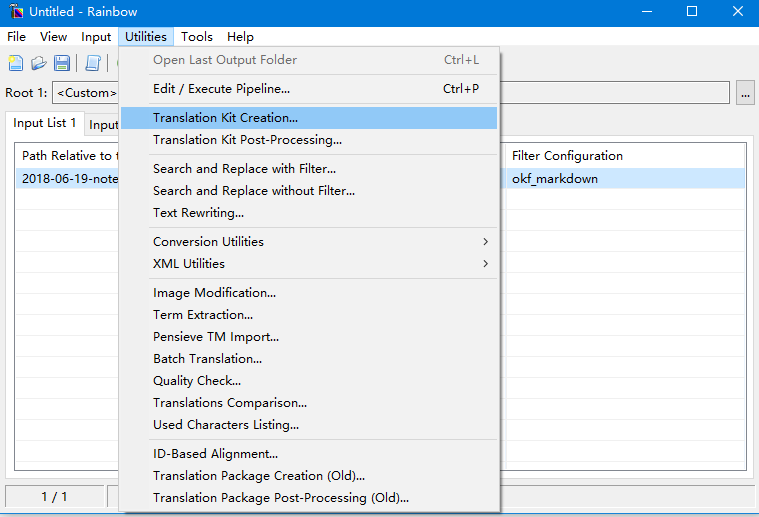
点击后使用默认的设置即可,然后点击Execute即可生成XLIFF文件。
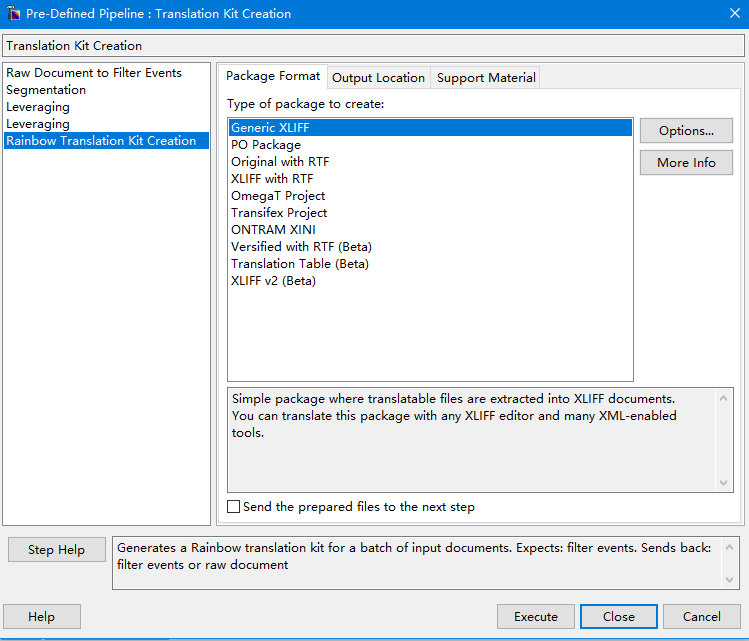
生成的文件夹如下图:
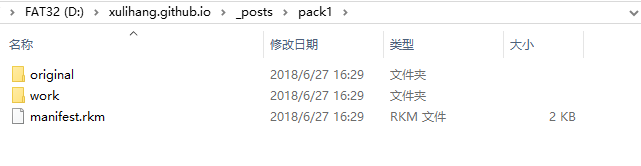
original里保存的原来的文件,work里是生成的需要翻译的XLIFF文件。XLIFF可以导入OmegaT进行翻译。
manifest.rfm是项目的声明文件。我们把该文件导入rainbow,可以进一步生成目标文件。
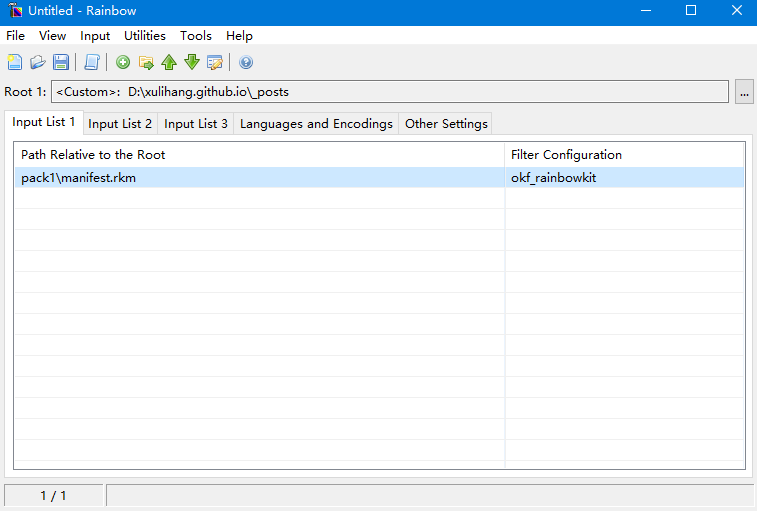
导入声明文件后选择Utilities->Translation Kit Post-Processing…
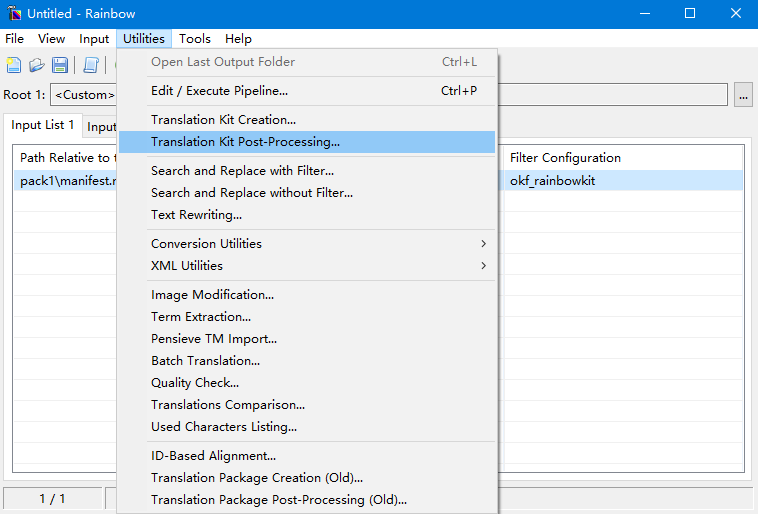
点击执行,并继续在弹出的创建中点击继续。
翻译好的目标文件就生成在项目文件夹的done文件夹里了。
以上是对于Markdown的处理,还有像restructuredText这样的标记语言,OmegaT和Okapi都不支持。好在restructuredText的写作工具Sphinx支持将restructuredText的文本提取到Gettext PO文件。GetText是GNU项目用来本地化程序的一套工具,逐渐成为一套本地化的标准。GetText和XLIFF类似,XLIFF是基于XML的,而GetText有自己的一套文件格式。
需要从源文件生成.pot模板文件,然后基于该文件生成对应的语言供翻译的po文件,po文件主要由msgid和msgstr构成:

翻译好后进一步生成二进制的mo文件,然后在生成网页或者PDF的成品时,Sphinx可以根据不同的语言,生成对应的目标文件。具体的步骤见此:http://www.sphinx-doc.org/
en/master/intl.html#sphinx-internationalization-details
建立项目
使用OmegaT新建项目,默认不需要进行额外设置。
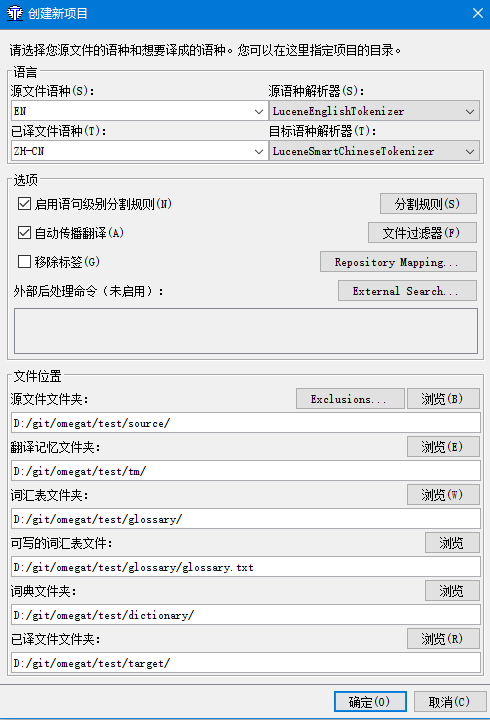
需要注意的是分割规则。
OmegaT中有两种类型的规则,中断规则和例外规则。
中断规则将源文本分割为片段。例如,”Did it make sense? I was not sure.” 应该分割成两个句子。要实现这样的目的,应该在 “?” 后跟着空格和大写字符时进行中断的规则。要定义一个中断规则,请选中中断/例外复选框。
例外规则指定哪部分文本不应该被分开。不考虑句点的话, “Mrs. Dalloway “ 不应被分割成两个片段,因此应该为后面跟着句点的 Mrs (以及 Mr 和 Dr 、prof 等等) 创建例外规则。要定义例外规则,请取消选中中断/例外复选框。
对于绝大多数欧洲语言和日语来说,预定义的中断规则已经够用了。我们可以根据情况进行自定义。OmegaT的分割规则以自己的格式进行存储在项目的omegat文件夹的segmentation.conf文件里。
之后,我们需要导入文件。如果文件的格式不支持,则会导入失败。
导入完成后,就可以进行翻译了。
项目统计
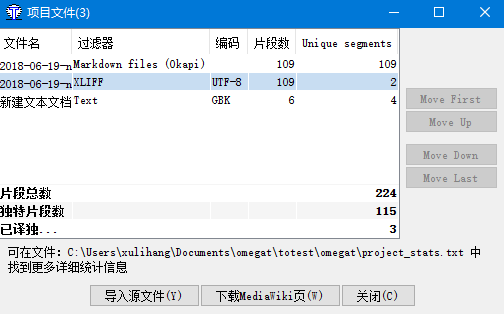
点击工具->统计,我们可以查看项目的统计信息。
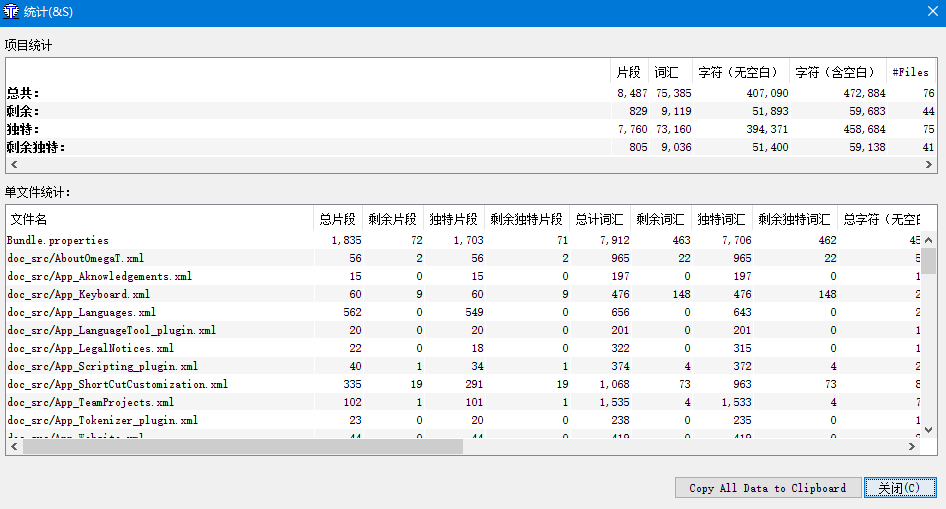
我们可以知道总共需要翻译多少字,有哪些重复的片段等等,在进行项目计划和报价的时候都可以用到。
术语管理
术语提取
本地化项目中往往存在很多专业术语,需要我们提前进行提取。我们可以使用Okapi的Rainbow进行操作。
添加源文件后,点击Utilities->Term Extraction。
下一步,可以设置输出文件的目录,输出结果是否要按词频进行排序,以及提取的词长等等。另外还可以设置停用词,这样提取出的词就会接近术语了。
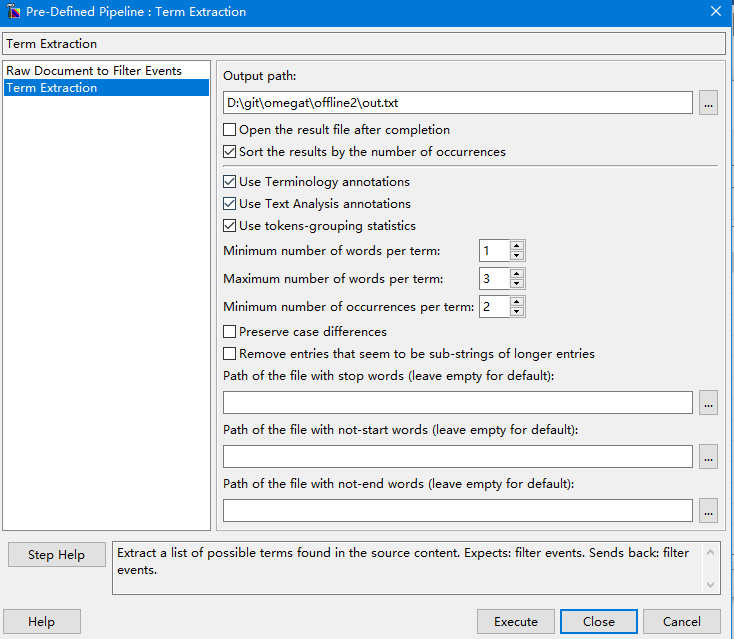
点击执行后就可以获得结果了:
之后我们对其进行翻译,保存为源文本、译文和注释以TAB分割的glossary.txt放入OmegaT项目的glossary文件夹,便可以作为术语库导入OmegaT中使用了。glossary.txt的内容如下:

建立术语条目
使用OmegaT进行翻译时,如果碰到术语,会在下方出现蓝色的标记(需要手动开启),在词汇表的窗口里显示术语库的记录。比如下图中识别到Context Menu是一个术语。
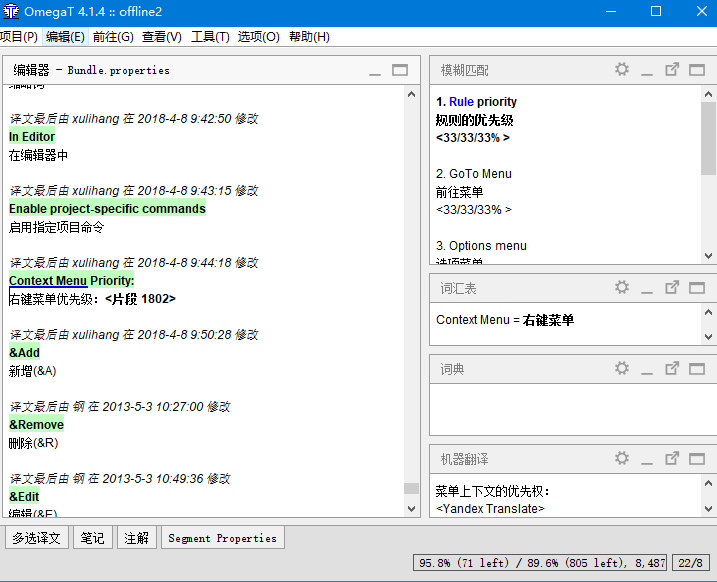
我们在翻译中碰到未添加的术语,可以手动添加进术语库。在词汇表窗口右键,点击增加词汇表条目。
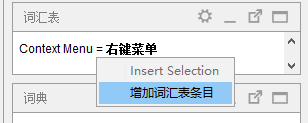
我们需要输入源词语和目标词语,另外也可以添加注释。
翻译记忆
本地化工程师还要管理翻译记忆。
OmegaT的翻译记忆文件
OmegaT使用tmx作为默认的翻译记忆存储格式,每翻译一个片段,就会保存一条翻译记忆。OmegaT项目含有在五个不同位置的翻译记忆文件,即扩展名为tmx的文件:
omegat文件夹包含project_save.tmx文件,以及一些备份的TMX文件。project_save.tmx文件包含了自项目开始以来所有被保存的片段。项目中总是存在此文件。其内容总是根据源片段的字母进行排序。
项目主文件夹中包含3个tmx文件:project_name-omegat.tmx,project_name-level1.tmx 以及project_name-level2.tmx(project_name 是项目的名称)。
level1文件仅包含文本信息。
level2文件以适当的 TMX 标签封装了OmegaT的特殊标签,因此它可以在支持第 2 级 TMX的翻译工具中使用其中的格式信息,包括 OmegaT 本身。
OmegaT文件包含了 OmegaT 特殊的格式标签,因此该文件可用于其他OmegaT项目。
这些文件是project_save.tmx文件的副本,即不包括被称为孤立片段的主翻译记忆。它们使用适当变化的名称,这样在其他地方使用时容易识别其中包含的内容,例如在其他项目的tm子文件夹(见下面)。
调用翻译记忆
本地化工程师可以把过往的翻译记忆放在OmegaT项目的tm文件夹下,这样在翻译时会自动显示匹配的翻译记忆。如果翻译记忆的质量很好,可以直接放在tm/auto文件夹下,这样100%匹配的片段会利用翻译记忆进行预翻译。而质量较差的翻译记可以放在tm/penalty-xxx文件夹里。xxx可以填写30、40等数字,表示罚分,比如原来匹配100%的,罚分后就变成70%了。
团队协作
一个本地化项目往往需要多人协作,开源工具对此也有支持。
OmegaT团队项目
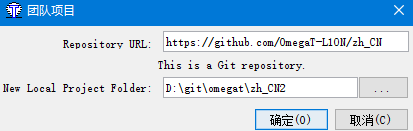
OmegaT支持基于git或者svn进行团队协作。以利用GitHub建立团队项目为例,我们需要先在本地建立一个OmegaT的项目,然后将项目的内容传到GitHub上的一个仓库里。需要注意的是使用.gitignore排除一些备份文件。target文件夹也不需要放入仓库。
完成后,点击下载团队项目,输入项目的地址,就可以将团队项目下载下来。
译员需要提交翻译,需要使用自己的GitHub账户进行登录,当然也需要对GitHub仓库有推送修改的权限。
Zanata
当然,除了使用OmegaT的团队功能之外,我们还可以用Rainbow生成PO文件,然后上传到Zanata或者Pootle这些在线本地化系统上进行协作。当然Zanata自己支持常见的一些格式。
质量管控
使用OmegaT自带的检查功能
翻译完成后,点击菜单工具->Check Issues,可以对翻译进行检查。
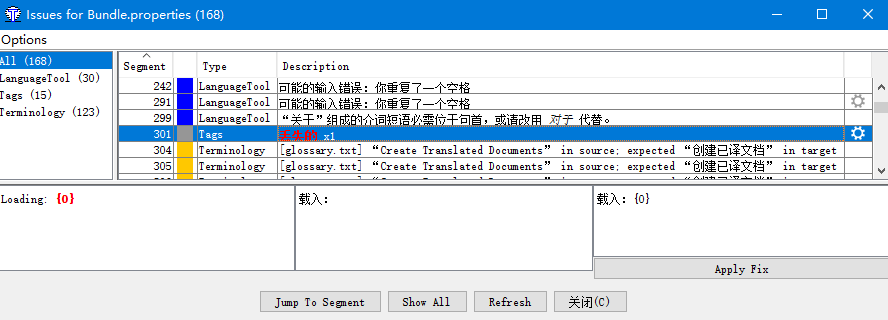
OmegaT会检测检查术语是否翻译得一致、有没有丢失标签。如果有装Language Tools插件的话,还会提示一些语法问题。
使用CheckMate
Okapi还提供了CheckMate这一质量检查工具。我们需要把生成的翻译记忆tmx文件导入。
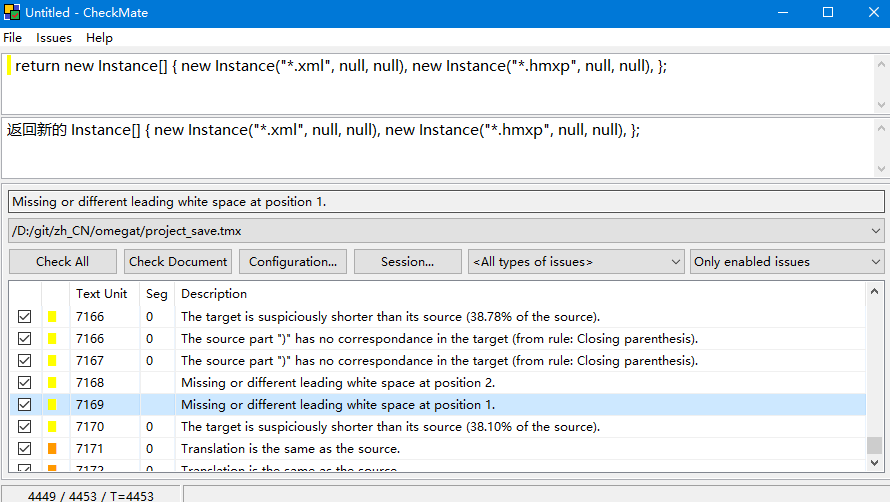
导入后点击check就可以显示错误了,涉及译文长度、译文有没有原文中对应的符号或者数字或者比译文多出哪些内容,具体可以点击configuration进行设置。
其它辅助功能的配置
语言词典
OmegaT支持基于StarDict或为Lingvo DSL格式的词典,将词典下载下来后,把dict.dz,idx和info扩展名的几个文件放到dictionary文件夹即可。
拼写词典
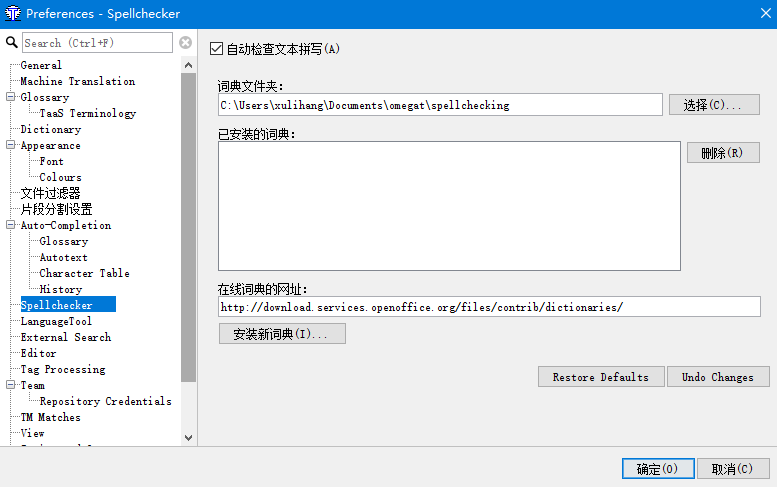
OmegaT内置有拼写检查器,它基于在Apache OpenOffice、LibreOffice、Firefox和Thunderbird中使用的拼写检查器。因此能使用在这些程序中可用的大量免费的拼写检查词典,供译员在进行翻译时就能检查拼写。点击菜单的选项->Preferences,
切换到Spellchecker的设置界面,在此,我们可以设置存放词典的文件夹和下载拼写检查词典。
机器翻译
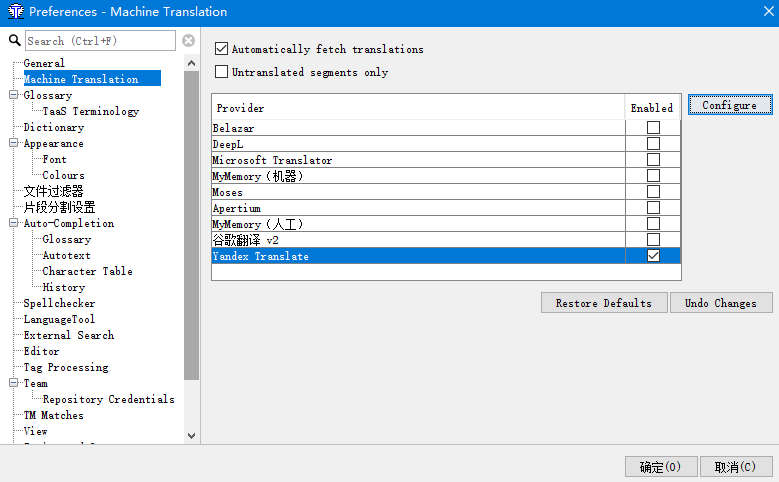
OmegaT支持调用多种机器翻译服务,可以为译员提供参考。
进入Machine Translation的设置界面,可以选择要启动的机器翻译。一般我们都需要都提供机器翻译服务的网站获取访问用的API密钥,才能使用机器翻译。Google和微软的目前要收费,Yandex是免费的。
使用Yandex机器翻译的效果如下:

使用脚本
OmegaT支持使用javascript和groovy作为脚本语言编写脚本。
点击菜单->工具->脚本,进入脚本窗口。
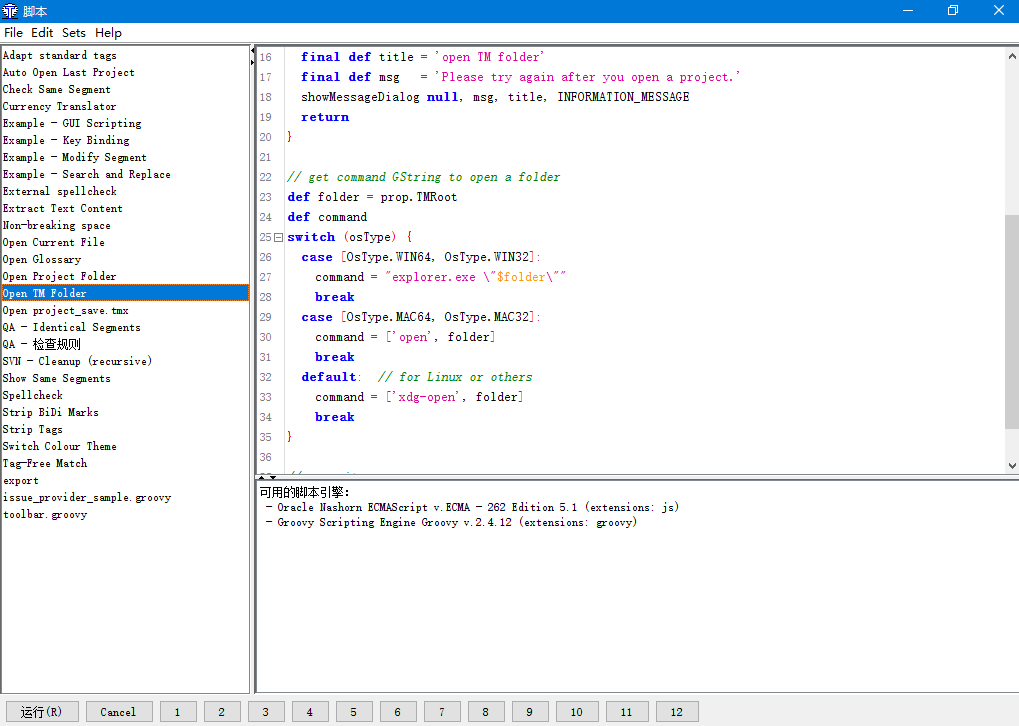
通过脚本我们可以自动执行一些批处理任务或者快捷操作,比如以片段顺序导出原文和译文,自己建立规则进行QA检查,快速打开项目文件夹等等。
结语
目前开源软件的功能和商业软件相差并不大,本地化工程师用好开源工具,往往已经足够应付日常工作的需要。