这两天给本站添加了全文检索功能,在此把过程做一个记录。
全文检索,顾名思义就是用关键词匹配全文,得到符合条件的内容。如果所需检索的内容不多,可以直接进行搜索。但如果内容比较多,像本博客算上这篇有400篇了,搜索的性能会比较糟糕。这个时候需要先建立索引,再进行搜索。
如果有后端的话,通常是由后端提供全文检索服务。但本站是个基于Jekyll的纯静态站点,只能选择Google CSE、Algolia这样的第三方服务或者直接在前端进行检索。
之前一篇博客介绍了如何用lunr.js在前端实现全文检索。它的一个缺点是对中文支持不佳,需要用nodejs在桌面去给中文建立索引。
时代在发展,这次我们选择用FlexSearch作为全文检索引擎。它有更好的性能和灵活性,可以自由配置以支持中英文检索。
使用FlexSearch检索中英文
为了让FlexSearch支持中英文检索,我们需要修改它的encode方法,把中文按字拆分,英文用单词拆分。比如“FlexSearch全文检索”,需要被拆分为“FlexSearch”、“全”、“文”、“检”、“索”。
我们可以用JavaScript的正则替换功能,给单个中文的两边加上空格,之后再根据空格split来做到这点。
下面是具体的代码:
let index = new FlexSearch.Index({
tokenize: "forward",
encode: str => str.replace(/[:"“”:]/g, " ").replace(/\n/g, " ").replace(/([\u4e00-\u9fa5])/g, " $1 ").split(" ")
});
这里还替换了冒号、换行、引号等内容,避免英文单词和它们相连时会检索不到的问题。
使用Liquid模板生成文章内容的JSON文件
我们需要把所有文章的内容保存成一个JSON文件,供前端使用。
我们可以用Liquid来实现。
-
在站点根目录建一个叫
posts.json的文件。 -
添加一段yaml头信息,这样构建站点时会把它视为一个liquid模板文件。
--- # Content for Full-Text Search layout: null --- -
使用Jekyll的Liquid保存站点内容为JSON。这里需要使用一系列filter来使内容符合JSON规范。保存的内容包含博客标题、正文、发布时间和URL。
{ "posts":[ {% for post in site.posts %}{ "id": {% increment index %}, "title": {{ post.title | jsonify }}, "date": {{ post.date | date:"%Y-%m-%d" | jsonify }}, "text": {{ post.content | strip_html | normalize_whitespace | jsonify }}, "url": {{ post.url | relative_url | jsonify }} }{%- unless forloop.last -%},{%- endunless -%} {%- endfor -%} ] }
最终在站点构建时会生成1MB多的一个JSON文件。gZip压缩后,实际传输的大小500KB不到。
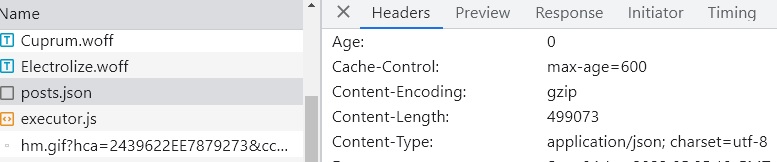
注意这里缓存时间只有10分钟,我们可以把这个JSON文件存到indexedDB里做持久存储,然后根据last-modified信息判断是不是要更新。
构建一个搜索页面
-
新建一个
search目录,在里面放一个index.html文件。--- title: 搜索 layout: default enableSearch: true --- <div> <input type="text" class="keywords"/> <label><input type="checkbox" class="matchAll" checked/>完全匹配</label> <button class="search-button">搜索</button> <span class="status"></span> </div> <div class="search-results"></div> <script src="/media/js/search.js"></script> -
修改默认的layout文件,如果页面启用了检索,从CDN引入FlexSearch。
<head> {% if page.enableSearch %} <script src="https://cdn.jsdelivr.net/gh/nextapps-de/flexsearch@0.7.31/dist/flexsearch.bundle.js"></script> {% endif %} </head> -
建立一个
search.js文件,用于存放对应的JS代码。 -
下载
posts.json并建立索引。需要建立索引的内容包含标题和正文。let index = new FlexSearch.Index({ tokenize: "forward", encode: str => str.replace(/[:"“”:]/g, " ").replace(/\n/g, " ").replace(/([\u4e00-\u9fa5])/g, " $1 ").split(" ") }); async function indexDocument(){ updateStatus("索引中……"); const jsonString = await downloadPosts(); const result = JSON.parse(jsonString); posts = result.posts; for (let i = 0; i < posts.length; i++) { const post = posts[i]; index.add(post.id,getContentToIndex(post)); } updateStatus(""); } function downloadPosts(){ return new Promise(function(resolve){ updateStatus("下载博客内容中……"); function reqListener() { updateStatus(""); resolve(this.responseText); } const req = new XMLHttpRequest(); req.addEventListener("load", reqListener); req.open("GET", "/posts.json"); req.send(); }); } function getContentToIndex(post){ return post.title + " " + post.text; } -
如果URL参数有keywords这项或者用户点击了搜索按钮,进行检索。检索时,用History API更新浏览器历史,URL中的检索词参数会有变化,执行前进和后退也能对应到之前的检索记录。使用History API的一个好处是页面不用刷新,不用重新建立索引,虽然建立索引基本上不花时间。
document.getElementsByClassName("search-button")[0].addEventListener("click",function(){ search(); }); window.addEventListener("popstate", (event) => { checkURLParamAndSearch(); }); function checkURLParamAndSearch(){ if (getURLParameter("keywords")){ document.getElementsByClassName("keywords")[0].value = getURLParameter("keywords"); search(); } } function search(){ updateStatus("搜索中……"); const keywords = document.getElementsByClassName("keywords")[0].value; const results = index.search(keywords); console.log(results); listSearchResults(results); const newURL = window.location.origin + window.location.pathname + "?keywords=" + encodeURIComponent(keywords); if (newURL != window.location.href) { history.pushState(null, null, newURL); } updateStatus(""); } -
在文章内容中查询关键词,截取它前后50个字符的内容用于在搜索结果中显示,并高亮关键词。
function getHighlights(content){ const keywords = document.getElementsByClassName("keywords")[0].value; let context = getContext(content, keywords); const regexForContent = new RegExp(keywords, 'gi'); // Replace content where regex matches context = context.replace(regexForContent, "<span class='hightlighted'>$&</span>"); return context; } function getContext(content,keywords){ const startIndex = Math.max(0,content.indexOf(keywords) - 50); const endIndex = Math.min(content.indexOf(keywords) + 50 + keywords.length, content.length); return content.substring(startIndex, endIndex)+"..."; }
下面是最终结果的截图:

全文检索还有很多可以优化的地方,比如大小写匹配、词型还原、模糊匹配、条件检索等等。用于本站的话,目前的功能也足够了。
其它方案
这里再收录些其它前端全文检索方案。
- 事先建立索引,检索时获取内容页面提供上下文。这个是Sphinx文档的处理方式(在线例子)。
……待补充