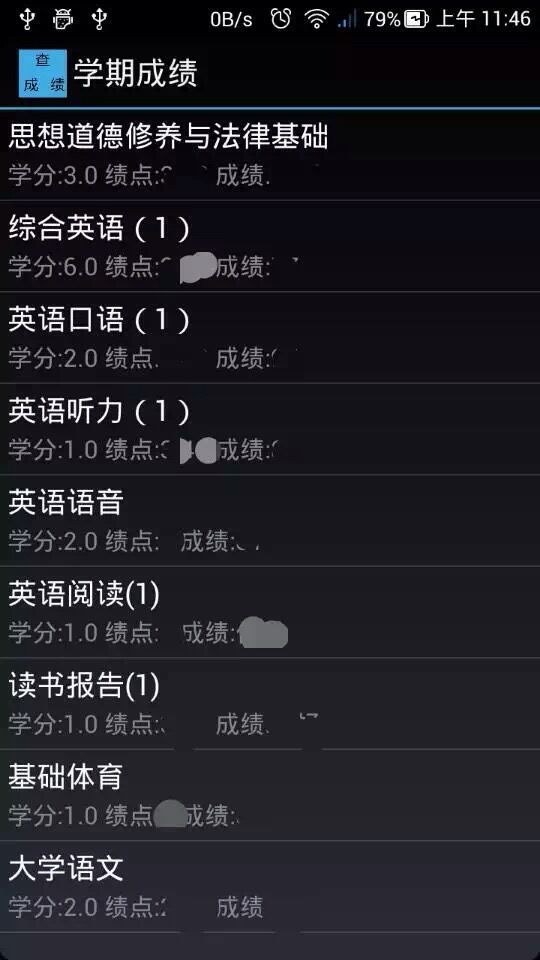
最近看到学促推出了新的叫“江南学子”的微信公众号,支持查课表和成绩。以前就想爬取成绩,但一直没有动手。既然有人做出来了,我也想自己试一试。
首先得把含有成绩的网页下下来吧。用火狐的插件httpfox抓包,分析网络请求。我一开始用的wireshark,但感觉没有httpfox好用,界面不够清楚。
##登录
我们学校默认的登录地址是http://jwxt.jiangnan.edu.cn/jndx/default2.aspx,相比其它学校,少了中间会动态变化的一串字符,显得容易一点。但默认地址要求输入验证码,还要搞一个验证码识别的话就加大了难度。还好,我找到了另外两个地址,不需要输验证码:http://jwxt.jiangnan.edu.cn/jndx/default6.aspx,http://jwxt.jiangnan.edu.cn/jndx/default_ysdx.aspx。
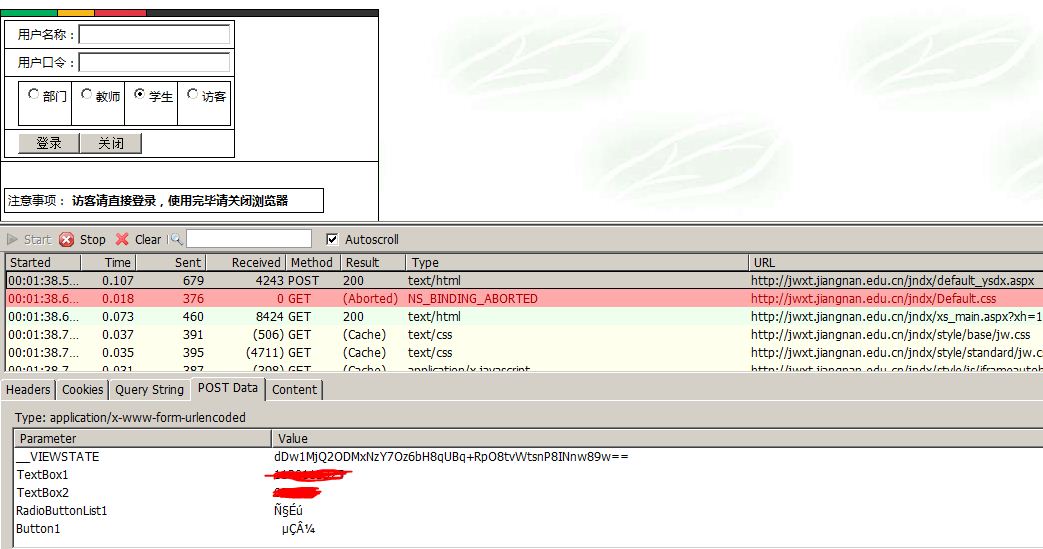
得知要POST的内容,用python测试。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
def login():
cookie = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
opener.addheaders = [('User-agent','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)')]
urllib2.install_opener(opener)
req = urllib2.Request("http://jwxt.jiangnan.edu.cn/jndx/default_ysdx.aspx")
req.add_header("Referer","http://jwxt.jiangnan.edu.cn/jndx/default_ysdx.aspx")
resp = urllib2.urlopen(req)
vs=getVIEW(resp.read())
req = urllib2.Request("http://jwxt.jiangnan.edu.cn/jndx/default_ysdx.aspx",urllib.urlencode({"__VIEWSTATE":vs,
"TextBox1":userid,
"TextBox2":passwd,
"RadioButtonList1":"学生",
"Button1":"登录"}))
req.add_header("Referer","http://jwxt.jiangnan.edu.cn/jndx/default_ysdx.aspx")
resp = urllib2.urlopen(req)
需要提交的有叫做__VIEWSTATE的数据,它会变化,所以我先获得了登录页面的内容,把__VIEWSTATE提取出来。返回的内容还是登录界面的内容,但登录成功的信息已经保存到cookie里了。
##获得成绩
在成绩查询页面下点击历年成绩,可以得到所有成绩信息。
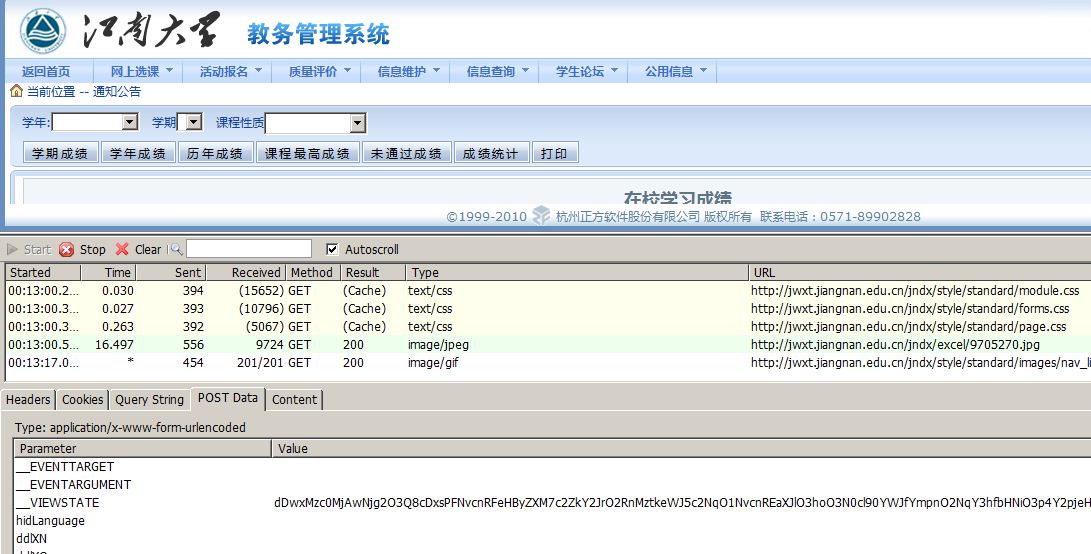
可以看到,需要post的参数很多,即使参数是空白的,也都需要发送。head照搬了httpfox下抓到的head。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
def login():
......
Cookie=""
for i in cookie:
Cookie = i.name+"="+i.value
head = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.8',
'Cache-Control':'no-cache',
'Connection':'keep-alive',
'Content-Type':'application/x-www-form-urlencoded',
'Host':'jwxt.jiangnan.edu.cn',
'Cookie':Cookie,
'Origin':'http://202.195.144.163',
'Pragma':'no-cache',
'Referer':'http://jwxt.jiangnan.edu.cn/jndx/default6.aspx',
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.76 Safari/537.36'
}
getdata = urllib.urlencode({'xh':userid,'xm':realname,'gnmkdm': 'N121605'})
req = urllib2.Request("http://jwxt.jiangnan.edu.cn/jndx/xscjcx.aspx?xh="+userid+"&xm="+realname+"&gnmkdm=N121605",getdata,head)
req.add_header("Referer","http://jwxt.jiangnan.edu.cn/jndx/default_ysdx.aspx")
resp = urllib2.urlopen(req)
page=resp.read()
vs=getVIEW(page)
head = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3',
'Cache-Control':'no-cache',
'Connection':'keep-alive',
'Content-Type':'application/x-www-form-urlencoded',
'Host':'jwxt.jiangnan.edu.cn',
'Cookie':Cookie,
'Origin':'http://jwxt.jiangnan.edu.cn',
'Pragma':'no-cache',
'Referer':'http://jwxt.jiangnan.edu.cn/jndx/xscjcx.aspx?xh='+userid+'&xm='+realname+'&gnmkdm=N121605',
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.76 Safari/537.36'
}
req = urllib2.Request("http://jwxt.jiangnan.edu.cn/jndx/xscjcx.aspx?xh="+userid+"&xm="+realname+"&gnmkdm=N121605",urllib.urlencode({"__VIEWSTATE":vs,'btn_zcj':'历年成绩',"__EVENTTARGET":"","__EVENTARGUMENT":"","hidLanguage":"","ddlXN":"","ddlXQ":"","ddl_kcxz":""}),head)
resp = urllib2.urlopen(req)
这样就把包含成绩的html抓下来了,接下来就要进行解析了。
##处理成绩
我不会正则,也不会其它的第三方解析软件,于是参看了github上的一些例子。但测试下来成绩不全。而且数据经过正则之后顺序乱了,虽然可以再排过,但也嫌麻烦。
我发现成绩的每行表格正好占了一行内容。只要读取每行的内容,在读的时候把<td></td>里的东西抠出来,就可以得到按学期排序的成绩了。最终我想得到一个字典,以第几学期为key,里面是一个列表,列表里面又包含了每门课成绩的列表。具体代码如下,我只用了<td>(.+?)</td>这个正则表达式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
def gen():
f=open('out')
count=len(f.readlines())
f=open('out')
result={}
singleterm=[]
termnum=1
term="0"
termname=""
havingreadlines=0
for line in f.readlines():
str2 = r"<td>(.+?)</td>"
str2 = re.compile(str2)
a = str2.findall(line)
havingreadlines=havingreadlines+1
if a!=[]:
if a[0].find("java")==-1 and a[0].find("span")==-1:
a.pop() #删除最后一项无用数据
if a[1]!=term: #若某学年学期(1 or 2)改变,记录一学期成绩到字典
if term=="0": #第一学期需要初始一下
term=a[1]
singleterm.append(a)
else:
termname="TERM"+str(termnum) #得到学期名
result[termname]=singleterm #记录一学期的成绩
termnum=termnum+1 #学期序数加一
term=a[1] #某学年学期改成新的
singleterm=[] #清空一学期的成绩记录
else:
singleterm.append(a)
if count==havingreadlines: #内容读到底了再记录一下
termname="TERM"+str(termnum)
result[termname]=singleterm
result=json.dumps(result, ensure_ascii=False)
return str(result)
最终的结果输出为json,方便客户端调用。
不要笑我代码写得丑,水平如此,能够达到目的,对我来说就不容易了。
最后布置到openshift上,再写个安卓客户端就显得比较实用了。我还加上了算绩点的功能。