首先讲一下机器学习中分类和聚类的区别。分类是有监督学习,比如使用做好标记的数据训练贝叶斯分类器判断邮件是不是垃圾邮件。而聚类是无监督学习,从一堆没有标记的数据中发现分类。
K-Means聚类需要用户指定K个分类,取随机K个种子点(质心),跟种子点近的数据可以归为一类。之后重新确定质心,看和原来的质心差别是不是不大,不大则大致可以完成聚类。
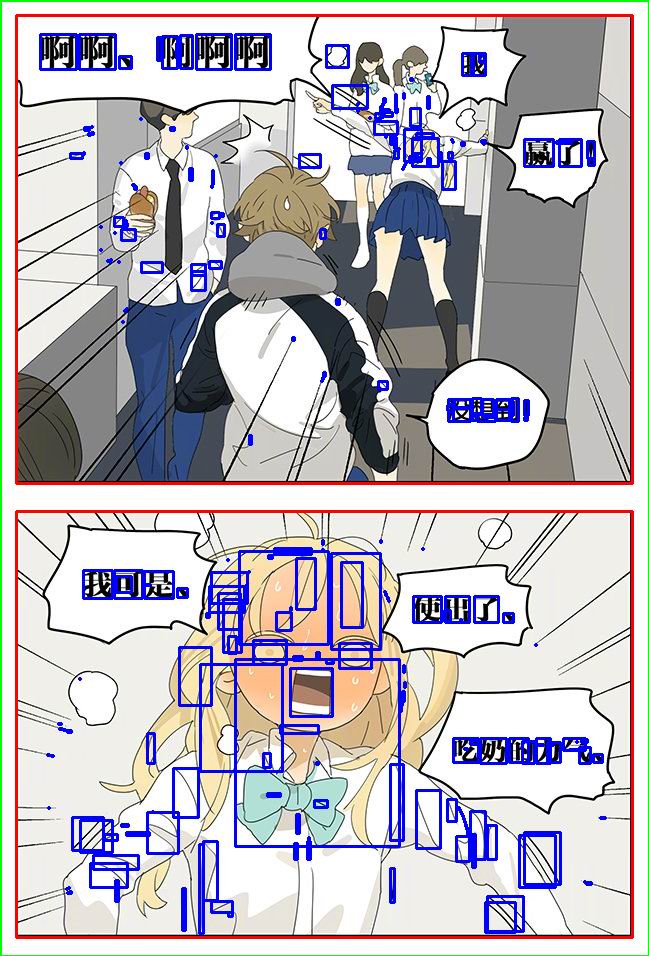
下面是一个应用示例,用于漫画分镜和文字的检测。
漫画由一张张分镜构成,分镜中包含漫画的主要内容。我们可以用连通区域标记方法对这些区域进行标记。

这些区域可以按高度进行划分,依次为整张图片、分镜、分镜中的内容。
我们使用Python-opencv获取连通区域的矩形框,然后用Python的sklearn机器学习库来使用KMeans聚类:
import cv2
import numpy as np
img = cv2.imread('3.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)[1]
_, labels, stats, centroids = cv2.connectedComponentsWithStats(thresh)
X=[]
for stat in stats:
h=stat[cv2.CC_STAT_HEIGHT]
one=[] #单个数据点,可以添加多个数据
one.append(h)
X.append(one)
kmeans_model = KMeans(n_clusters=3) #设置分类为3
y_pred= kmeans_model.fit_predict(X)
print(y_pred) #输出分类结果
index=0
#不同分类设置不同颜色
color1=(255,0,0)
color2=(0,255,0)
color3=(0,0,255)
cls1=[]
cls2=[]
cls3=[]
for cls in y_pred:
if cls==0:
color=color1
cls1.append(stats[index])
elif cls==1:
color=color2
cls2.append(stats[index])
else:
color=color3
cls3.append(stats[index])
stat=stats[index]
x=stat[cv2.CC_STAT_LEFT]
y=stat[cv2.CC_STAT_TOP]
w=stat[cv2.CC_STAT_WIDTH]
h=stat[cv2.CC_STAT_HEIGHT]
cv2.rectangle(img, (x, y), (x + w, y + h), color, 2)
index=index+1
cv2.imwrite('labeled.png', img)
cv2.namedWindow("labeled.png",cv2.WINDOW_NORMAL)
cv2.imshow('labeled.png', img)
cv2.waitKey()
最后输出结果如下: