memoQ的产品经理写了一个介绍本地化iOS应用的系列文章,Localizing an iOS drawing app with memoQ, one cliffhanger at a time。
主要分为以下步骤:
-
建立一个基于正则的文本过滤器(Regex Text Filter),解析含有类似以下内容的语言资源文件:
/* Distribute Horizontally */ "Distribute Horizontally" = "Distribute Horizontally"; /* Distribute Vertically */ "Distribute Vertically" = "Distribute Vertically"; /* Download Problem */ "Download Problem" = "Download Problem"; /* Downloading “%@” */ "Downloading “%@”" = "Downloading “%@”"; -
将占位符解析为标签。
有的文本中存在占位符,程序运行时会将它们替换为对应的数据,比如以下这样的:
Downloading “%@” Delete %d Drawings这类占位符很容易翻译错误,而且会影响字数统计。这时可以把它们当做标签处理,相当于把这些内容当做非译元素进行处理。设置后的结果如下:

-
使用伪翻译验证能否正常生成文件。
伪翻译(pseudo-translation)能用目标语言文字按一定的原文译文比填充译文,我们可以用它来检查是否能生成正确的文件。
我们也可以选择用机器翻译进行填充,但是调用需要时间和费用。
-
用TransPDF转换PDF为XLIFF。
这里,作者还想把软件的英文和匈牙利文的PDF文档做一个对齐操作,可以作为翻译记忆进行调用。首先使用了TransPDF的转换功能。
-
使用LiveDocs功能进行对齐。
作者首先过滤了如页码这样不需要的信息,然后,使用LiveDocs对之前用TransPDF提取的两个XLIFF文件进行对齐。这样直接自动对齐的结果有偏差,但基本上偏差只有几个片段的距离,正确对齐的还是占很大的部分。一个实际的用途是在检索时能够看到原文的词对应译文中的哪个词。
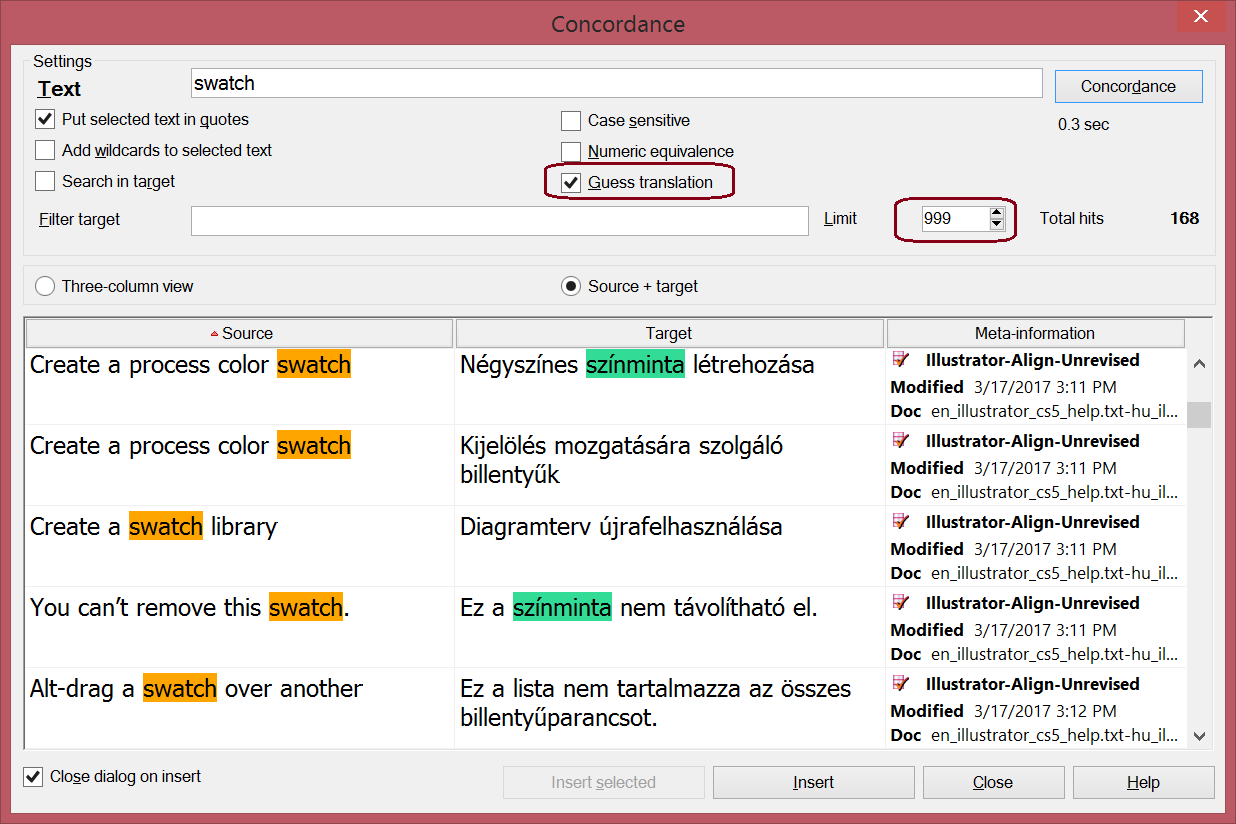
以上工作准备好后,剩下的就是翻译了。
以上是作者收到语言资源文件后用memoQ进行的操作。关于导出XLIFF来本地化iOS/macOS的应用,可以见我另一篇文章:iOS/macOS应用的本地化。