NLTK是常用的Python自然语言处理库,因为它把算法、模型和语料等都封装好了,我们只需学会怎么使用。因此,这篇文章主要的作用是记录如何使用nltk。使用的例子都是来自nltk cookbook这本书。
切分(Tokenization)
切分可以分为句子切分和词切分,nltk默认用PunktSentenceTokenizer分句,用基于宾州树库分词规范的TreebankWordTokenizer分词。具体用以下命令做到:
#句切分
>>> para = "Hello World! Isn't it good to see you? Thanks for buying this book."
>>> from nltk.tokenize import sent_tokenize
>>> sent_tokenize(para)
['Hello World!', "Isn't it good to see you?", 'Thanks for buying this book.']
#词切分
>>> from nltk.tokenize import word_tokenize
>>> word_tokenize('Hello World.')
['Hello', 'World', '.']
默认的分词在遇到can’t这样的缩写(contraction)时会分成ca和n’t,如果不喜欢,可以用dir(nltk.tokenize)查看别的分词器并使用。
我们还可以用正则来进行切分。上面提到的方法不支持中文,我们可以用正则来做一个中文分句(中文分词就太难了),方法如下:
#中文正则分句
>>> from nltk.tokenize import RegexpTokenizer
>>> tokenizer = RegexpTokenizer(".*?[。!?]")
>>> tokenizer.tokenize("世界真大。我想去看看!你想去吗?不了。")
['世界真大。', '我想去看看!', '你想去吗?', '不了。']
词性标注
对句子进行词性标注需要先进行切分。默认使用的标记格式是宾州树库使用的,具体见此:Alphabetical list of part-of-speech tags used in the Penn Treebank Project
>>> import nltk
>>> sentence = """At eight o'clock on Thursday morning
... Arthur didn't feel very good."""
>>> tokens = nltk.word_tokenize(sentence)
>>> tokens
['At', 'eight', "o'clock", 'on', 'Thursday', 'morning',
'Arthur', 'did', "n't", 'feel', 'very', 'good', '.']
>>> tagged = nltk.pos_tag(tokens)
>>> tagged[0:6]
[('At', 'IN'), ('eight', 'CD'), ("o'clock", 'JJ'), ('on', 'IN'),
('Thursday', 'NNP'), ('morning', 'NN')]
命名实体识别
命名实体识别类似于一种chunking,可以把是命名实体的部分括起来,需要在标记的文本基础上进行。
>>> entities = nltk.chunk.ne_chunk(tagged)
>>> entities
Tree('S', [('At', 'IN'), ('eight', 'CD'), ("o'clock", 'JJ'),
('on', 'IN'), ('Thursday', 'NNP'), ('morning', 'NN'),
Tree('PERSON', [('Arthur', 'NNP')]),
('did', 'VBD'), ("n't", 'RB'), ('feel', 'VB'),
('very', 'RB'), ('good', 'JJ'), ('.', '.')])
句法分析
NLTK有自带宾州树库等树库,但是自身没有对生文本进行句法分析的能力,需要调用stanford parser等外部工具。
>>> from nltk.corpus import treebank
>>> t = treebank.parsed_sents('wsj_0001.mrg')[0]
>>> t.draw()
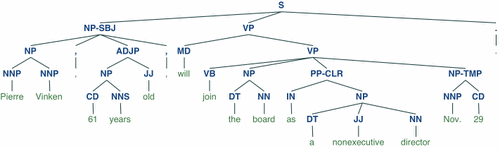
tree类有很多方法可以调用,比如可以用fromstring从文本生成tree类。
如何遍历tree可以见nltk的官方教程:http://www.nltk.org/book/ch07.html#code-traverse
WordNet的使用
WordNet可以被看作是一个同义词词典。里面的词都是以同义词集合(synset)作为基本建构单位进行组织。
我们可以用以下方法查看某个词的近义词,并可以用来判断这个词存不存在:
>>> from nltk.corpus import wordnet
>>> wordnet.synsets("pig")
[Synset('hog.n.03'), Synset('slob.n.01'), Synset('hog.n.01'), Synset('bull.n.05'), Synset('pig_bed.n.01'), Synset('pig.n.06'), Synset('pig.v.01'), Synset('devour.v.04'), Synset('farrow.v.01')]
>>> wordnet.synsets("piiig")
[]
其它还有查看上下位词、反义词,语义相似计算等功能,就不细讲了。
词干提取和词形还原
词干提取(stemming)就是把词的前缀后缀给去掉,使用代码如下:
>>> from nltk.stem import PorterStemmer
>>> stemmer = PorterStemmer()
>>> stemmer.stem('cooking')
'cook'
词形还原(lemmatization)则会把词转换为最基本的词,方法如下:
>>> from nltk.stem import WordNetLemmatizer
>>> lemmatizer = WordNetLemmatizer()
>>> lemmatizer.lemmatize('cooking') 'cooking'
>>> lemmatizer.lemmatize('cooking', pos='v')
'cook'
>>> lemmatizer.lemmatize('cookbooks')
'cookbook'
我们可以发现,lemma需要根据词性来进行还原,比如cooking作为名词,它本身就是一个lemma,而做动词使用时lemma是cook。所以像斯坦福CoreNLP进行词形还原时都需要先进行词性标注。
词干提取和词形还原的主要差别还可以从以下例子中看出来
>>> from nltk.stem import PorterStemmer
>>> stemmer = PorterStemmer()
>>> stemmer.stem('believes')
'believ'
>>> lemmatizer.lemmatize('believes')
'belief'
编辑距离与拼写检查
nltk自带了算编辑距离的代码,可以用以下方式调用:
>>> from nltk.metrics import edit_distance
>>> edit_distance("你好","你很好")
1
拼写检查需要使用编辑距离。比如across被拼成了acress,和它相近的有actress,caress等,一般编辑距离都要小于2。我们可以用pyenchant这个库来给出修改建议,并根据编辑距离进行筛选。
nltk中的语料库
最简单的一种语料库是词列表(wordlist)语料库,每行是一个单词。nltk中的停用词和人名语料库就是这一种类的。
第二种语料库是标注词性(Part-of-speech tagged)的语料库,比如brown语料库。词性以类似/NOUN的形式附在单词后面。
第三种语料库是对语块进行了分割的语料库(chunked phrase corpus),比如宾州树库。它除了有词性标注外,还有句法树的信息,利用方括号来存储在文本中。
第四种是分类语料库(categorized text corpus),brown是分类语料库,每个分类单独存在一个文件里。
待更新……
NLTK官方教程,值得一读:Natural Language Processing with Python