最近收到一个单元格内包含HTML内容的Excel文件。Excel文件其实类似于数据库,所以里面可能会存储各种各样类型的内容,常见的一种就是HTML。
HTML作为标记文本,还是比较容易处理的。但是内嵌在Excel里,用CAT软件处理的话就不是很容易。
于是我想出了一个方法:
- 将Excel单元格中的HTML内容导出为HTML文件,命名方法是“行号-列数.html”。
- 用CAT软件翻译这些HTML,我这里选择了OmegaT。
- 翻译好后再进行导回。
我基于Apache POI写了一个处理软件:ExcelCell-Replacer
对于这类复杂的情况一般只有自己写工具处理。不过对于像Trados这样,不断获得用户反馈的软件,它的功能基本上能应对各种需要。比如Excel内嵌HTML这种情况,可以使用Trados的嵌入内容处理器。
具体的操作和配置文件可以见此文:Translating Excel files with embedded HTML content in SDL Trados Studio
在项目设置里,要选择应用于文档中的哪些结构,比如单元格(sdl:cell)。之后定义规则。标记内容的处理主要还是依赖于正则表达式。
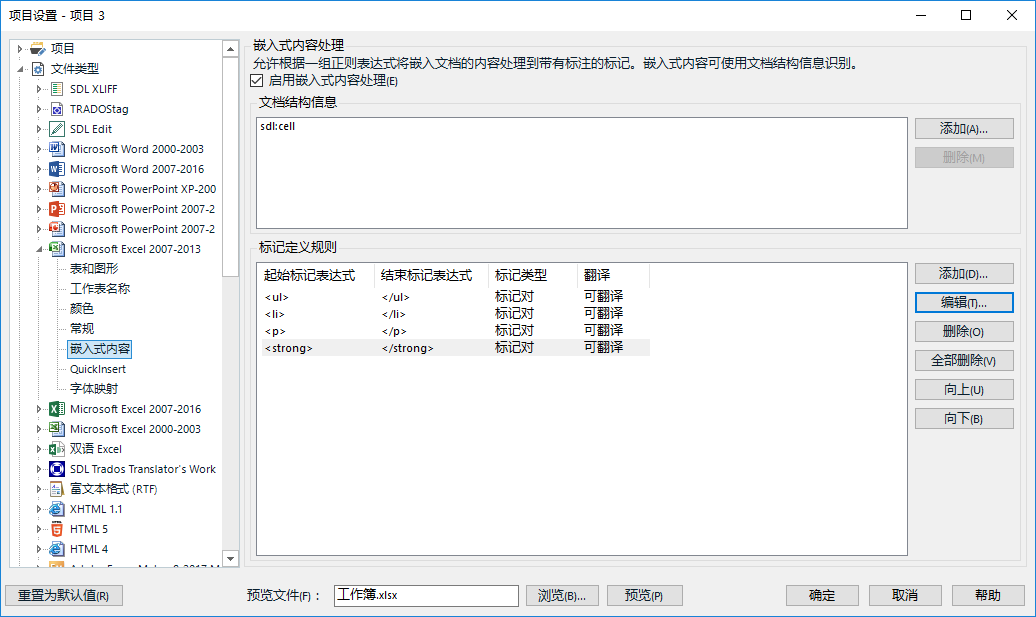
可以设置是标记对(比如HTML的段落标签)还是占位符(比如HTML的换行标签)。可以根据标签的属性赋予格式,比如strong标签表示加粗。
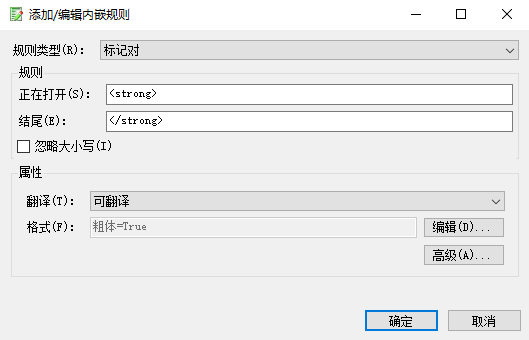
在高级设置里可以设置是包含还是排除标签,以及是否能够隐藏标签等等。
如果不排除标签,翻译时会显示标签:

设置排除后效果如下:

但并不是所有标签都应该排除,比如strong是行内标签,用于格式化部分文字。

这时我们可以更进一步,设置strong标签对应的样式,并设置为隐藏标签。最后结果如下:
